Fairer Preferences Elicit Improved Human-Aligned Large Language Model Judgments
Abstract
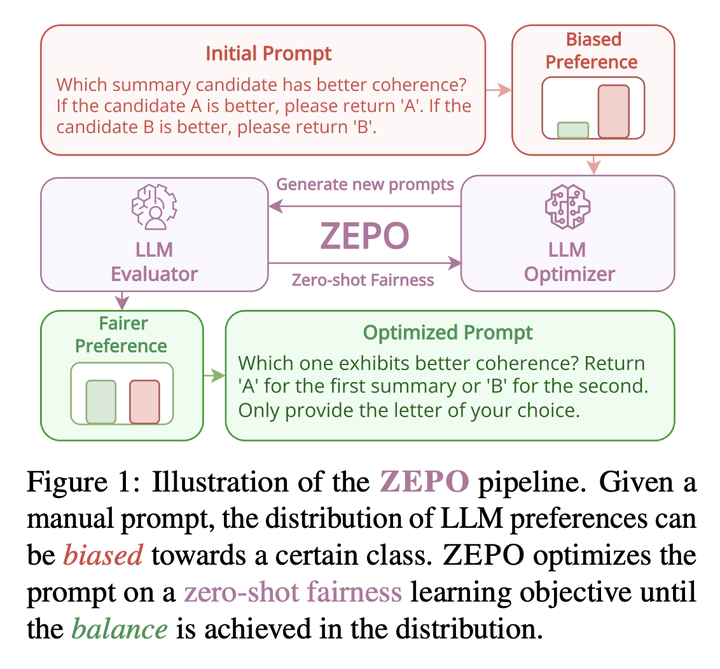
Large language models (LLMs) have shown promising abilities as cost-effective and reference-free evaluators for assessing language generation quality. In particular, pairwise LLM evaluators, which compare two generated texts and determine the preferred one, have been employed in a wide range of applications. However, LLMs exhibit preference biases and worrying sensitivity to prompt designs. In this work, we first reveal that the predictive preference of LLMs can be highly brittle and skewed, even with semantically equivalent instructions. We find that fairer predictive preferences from LLMs consistently lead to judgments that are better aligned with humans. Motivated by this phenomenon, we propose an automatic Zero-shot Evaluation-oriented Prompt Optimization framework, ZEPO, which aims to produce fairer preference decisions and improve the alignment of LLM evaluators with human judgments. To this end, we propose a zero-shot learning objective based on the preference decision fairness. ZEPO demonstrates substantial performance improvements over state-of-the-art LLM evaluators, without requiring labeled data, on representative meta-evaluation benchmarks. Our findings underscore the critical correlation between preference fairness and human alignment, positioning ZEPO as an efficient prompt optimizer for bridging the gap between LLM evaluators and human judgments.
Xingchen Wan
Senior Research Scientist
My research interests include large language models, Bayesian optimization, AutoML, and machine learning on graphs.