Introducing Self-Adaptive Prompting for Large Language Models
Adaptive, black-box and automatic prompting methods to improve large language models in zero-shot settings.
 Overall pipeline of COSP/USP
Overall pipeline of COSP/USP
3 Nov 2023: COSP and USP have also been covered in a recent Google Research blog – click for more details!
This post introduces a recent work done during my internship at Google Cloud AI Research covering the following papers:- Xingchen Wan, Ruoxi Sun, Hanjun Dai, Sercan Ö. Arık, Tomas Pfister (2023). Better Zero-Shot Reasoning with Self-Adaptive Prompting. Findings of the Association for Computational Linguistics: ACL 2023.
- Xingchen Wan, Ruoxi Sun, Hootan Nakhost, Hanjun Dai, Julian Martin Eisenschlos, Sercan Ö. Arık, Tomas Pfister (2023) Universal Self-Adaptive Prompting. Empirical Methods in Natural Language Processing (EMNLP).
The recent advances in large language models (LLMs) are among the most astonishing breakthroughs in the history of artificial intelligence. A hallmark feature of the modern LLMs is their impressive abilities in general problem-solving in few-shot and zero-shot setups, even without explicit training on these tasks. There is, however, still a gap between few-shot and zero-shot setup: in few-shot, the models are shown in-context demonstrations like the example below (taken from the chain-of-thought (CoT) paper) – the first question-answer pair is the demonstration prepended to the actual question being asked (the second question):
Q: There are 15 trees in the grove. Grove workers will plant trees in the grove today. After they are done, there will be 21 trees. How many trees did the grove workers plant today?
A: Let’s think step by step. There are 15 trees originally. Then there were 21 trees after some more were planted. So there must have been 21 - 15 = 6. The answer is 6.
Q: If there are 3 cars in the parking lot and 2 more cars arrive, how many cars are in the parking lot?
A: Let’s think step by step.
In zero-shot, in contrast, the LLM is directly prompted with the test question only (i.e., without the first question-answer pair shown above).
Zero-shot is the most general as it requires no handcrafting and is the most natural way of asking things. However, zero-shot performance is typically weaker as the LLM is not shown with model answers and thus is prone to outputting spurious answers.
Why don’t we simply handcraft some demos if it is “few”-shot?
You certainly can – modern LLMs are great because they can work with a handful of labeled queries (as opposed to hundreds to thousands if you fine-tune them).
However, there are examples where this can be challenging if, for example,
- You have a lot of tasks, and you end up having to handcraft
n_task * n_shot,which can be pretty big even ifn_shotis moderate. - Test queries are challenging or time-consuming in the first place (e.g., summarising a long article, answering a medical question that requires expertise or at least some research, or simply the example above: to do chain-of-thought prompting you have to solve a math question by hand first – quite a challenge for people like me who have graduated from primary school for too long.
Can we have demonstrations even in zero-shot?
We know that LLMs benefit from demonstrations (otherwise, few-shot won’t be better!), and we know that LLMs have at least some zero-shot abilities. So the natural next step is…
Why not use the model’s own outputs as demonstrations?
Several previous works have proposed this, like AutoCoT: We ask the LLMs to give answers under zero-shot prompting and prompt the models again with their outputs as demonstrations. A problem, though, is precisely what we mentioned just now – zero-shot solutions are imperfect, and we risk giving LLMs wrong demonstrations, which in some cases can be worse than no demonstrations at all. So the question now is…
Can we select good outputs as demonstrations without verifying their correctness?
A trivial way is to sift through the zero-shot outputs and retain correct answers. This, however, substitutes the manual effort in hand-labelling demos in the few-shot setup with hand-verifying outputs in zero-shot answers and defeats our purpose of achieving automatic prompting.
This is where self-adaptive prompting comes in: the TL;DR of the key idea is:
Confident and consistent answers from the LLMs are more likely correct.
This, of course, depends on how good the uncertainty estimate the LLMs have, but in large models, both previous works like this and this and our results have shown that they are fairly well-calibrated.
To measure confidence, we borrow the self-consistency idea (but not just for majority vote): In Consistency-Based Self-Adaptive Prompting (COSP), our ACL 2023 paper, we ask the same question multiple times but with a non-zero temperature to induce stochasticity: if the model is certain, it should output the same answer each time and vice versa. We then compute the entropy of the answers to gauge the uncertainty.
We later generalize this simple idea in Universal Self-Adaptive Prompting to two additional setups for general NLP tasks beyond reasoning:
- Classification (CLS), where we have the output logits – we can measure the uncertainty there without multiple sampling
- Short-form generation (SFG), like question answering, we can use the same procedure mentioned above for COSP, but without the rationale-generating step.
- Long text generation (LFG), like summarization and translation, the questions are often open-ended. The outputs are unlikely to be identical verbatim even if the LLM is certain, given the generation length and the fact that multiple answers can be equally plausible, we use an overlap metric instead by computing the average of the pairwise ROUGE score between the different outputs to the same query.
We compute the relevant confidence scores depending on the type of task on the aforementioned set of unlabeled test samples. After scoring, we pick the confident outputs, plus some diversity encouragement and repetition penalty, to form a model-generated pseudo-demonstration set. We finally query the LLM again in a few-shot format with these pseudo-demonstrations to obtain the final predictions on the entire test set.
Crucially, in all cases, this only requires unlabeled data and LLM outputs but no ground-truth labels at any point in time, and thus, the entire approach is zero-shot, or more precisely transductive zero-shot. There are several additional things to the idea above, and please check the papers for the details.
Putting all together

Putting all together, we have the following pipeline,
- Run zero-shot prompting to obtain a bunch of outputs on some test outputs, using self-consistency as mentioned above if necessary.
- Use the procedure described to score these outputs, and select the confident outputs as demos (plus some diversity encouragement and/or repetition penalty).
- Using the outputs obtained in Step 2 as pseudo-demos, query the LLM again in a few-shot format to get the final predictions.
… which is what we show in the cover picture of this post.
Results
On COSP, which focuses on reasoning tasks:
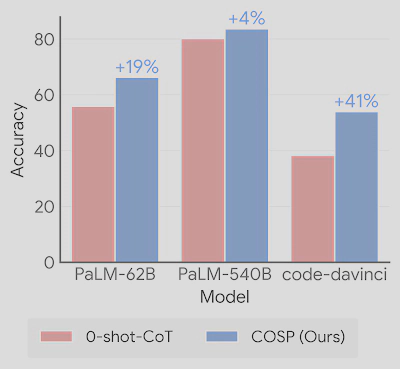
We can see that zero-shot COSP massively outperforms standard zero-shot (Let’s think step by step only) and is on par or better than 5-shot with labeled examples over 3 LLMs. We also outperform previous SoTAs like AutoCoT (shown in the paper). See the papers for more results and analyses!
In USP, we expand our analysis to a much wider range of tasks, including more than 25 classifications, short-form generation, and long-form generation tasks. We also study the BIG-Bench Hard suite of tasks where LLMs previously underperformed humans using the state-of-the-art PaLM 2 models. We show that in all cases, USP again outperforms the baselines and is competitive to prompting with golden examples.
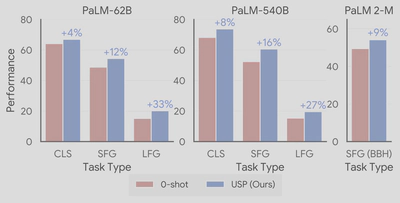
We also analyze the working mechanism of USP by validating the key observation above on the relation between confidence and correctness, and we found that in an overwhelming majority of the cases, USP picks confident predictions that are more likely better in all task types considered, as shown in the figure below.

Conclusion
Zero-shot inference is a highly sought-after capability of modern LLMs, yet the success in which poses unique challenges. We propose COSP and USP, a family of versatile, zero-shot automatic prompting techniques applicable to a wide range of tasks. We show large improvement over the state-of-the-art baselines over numerous task and model combinations.
Acknowledgements
This work was conducted by Xingchen Wan, Ruoxi Sun, Hootan Nakhost, Hanjun Dai, Julian Martin Eisenschlos, Sercan Ö. Arık, and Tomas Pfister. We would like to thank Jinsung Yoon and Xuezhi Wang for providing helpful reviews, and other colleagues at Google Cloud AI Research for their discussion and feedback.
Xingchen Wan
Senior Research Scientist
My research interests include large language models, Bayesian optimization, AutoML, and machine learning on graphs.