Xingchen Wan
Senior Research Scientist, ![]()


1600 Amphitheatre Parkway
Mountain View, CA 94043
xingchenw[at]google.com
I am a Senior Research Scientist at Google DeepMind based in the San Francisco Bay Area.
research interests
My primary research drives innovations in large language models (LLMs), focusing on building LLM agents that are more efficient, robust, and autonomous. My contributions span:
- Post-training (e.g., [1, 2, 3, 4]);
- Self-improving agents (e.g., [5, 6, 7]);
- Automating agentic designs (e.g., [8, 9, 10]); and
- GenAI with large-scale (unstructured) data systems (e.g., [11, 12]).
Previously, I did my PhD in the Machine Learning Research Group, Department of Engineering Science, University of Oxford where I worked on Bayesian optimization, AutoML, and machine learning on graphs.
academic services
Area chair/senior program committee member at ICML (2025, 2026), NeurIPS (2024, 2025), ACL ARR (2025-); Action editor at TMLR.
Reviewer/program committee member at ACL (2023-24), AutoML-Conf (2023-24), COLM (2024), CVPR (2024), ECCV (2024), EMNLP (2023-24), ICLR (2024-25), ICML (2023-24), JMLR, Machine Learning, NeurIPS (2022-23), WACV (2022-24), etc.
news
| Feb 20, 2026 | Our paper VISTA: A Test-Time Self-Improving Video Generation Agent has been accepted to CVPR 2026! |
|---|---|
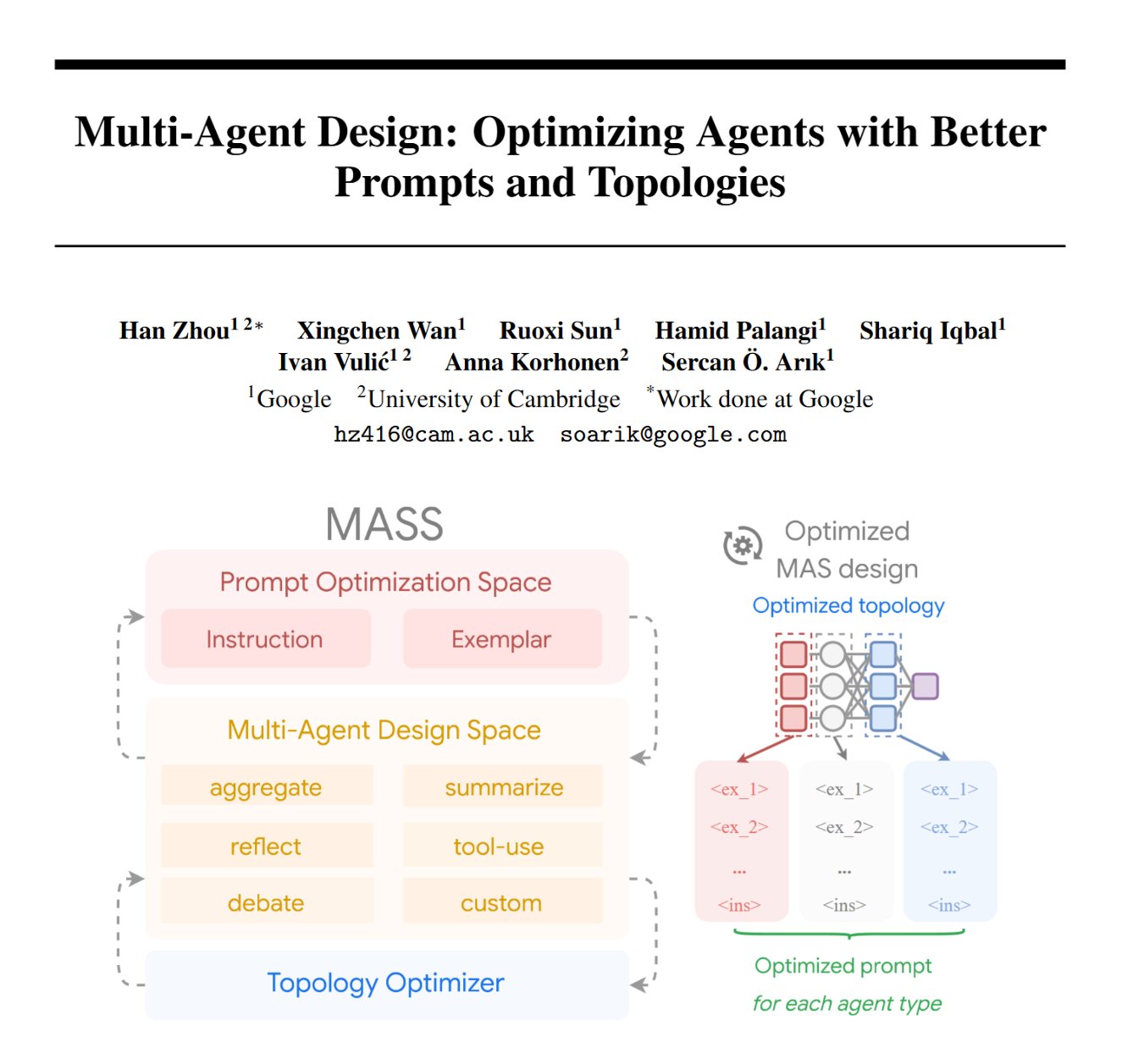
| Feb 05, 2026 | Two papers have been accepted to ICLR 2026: Visual Planning with Reinforcement Learning (Oral) and MASS (Optimizing Agents with Better Prompts and Topologies). |
| Oct 17, 2025 |
We present VISTA and Maestro, two self-improving multimodal generation agents for text-to-video and text-to-image generation, respectively.
|
| May 19, 2025 |
We present Visual Planning, where we apply reinforcement learning post-training on pure-vision models to achieve state-of-the-art performance in visual reasoning tasks.

|
selected publications
-
ICLR 2026
 Visual Planning: Let’s Think Only with ImagesThe Fourteenth International Conference on Learning Representations (to appear). 🏆🥉 #3 paper of the day at HuggingFace 🤗 , 2026
Visual Planning: Let’s Think Only with ImagesThe Fourteenth International Conference on Learning Representations (to appear). 🏆🥉 #3 paper of the day at HuggingFace 🤗 , 2026 -
NeurIPS 2024
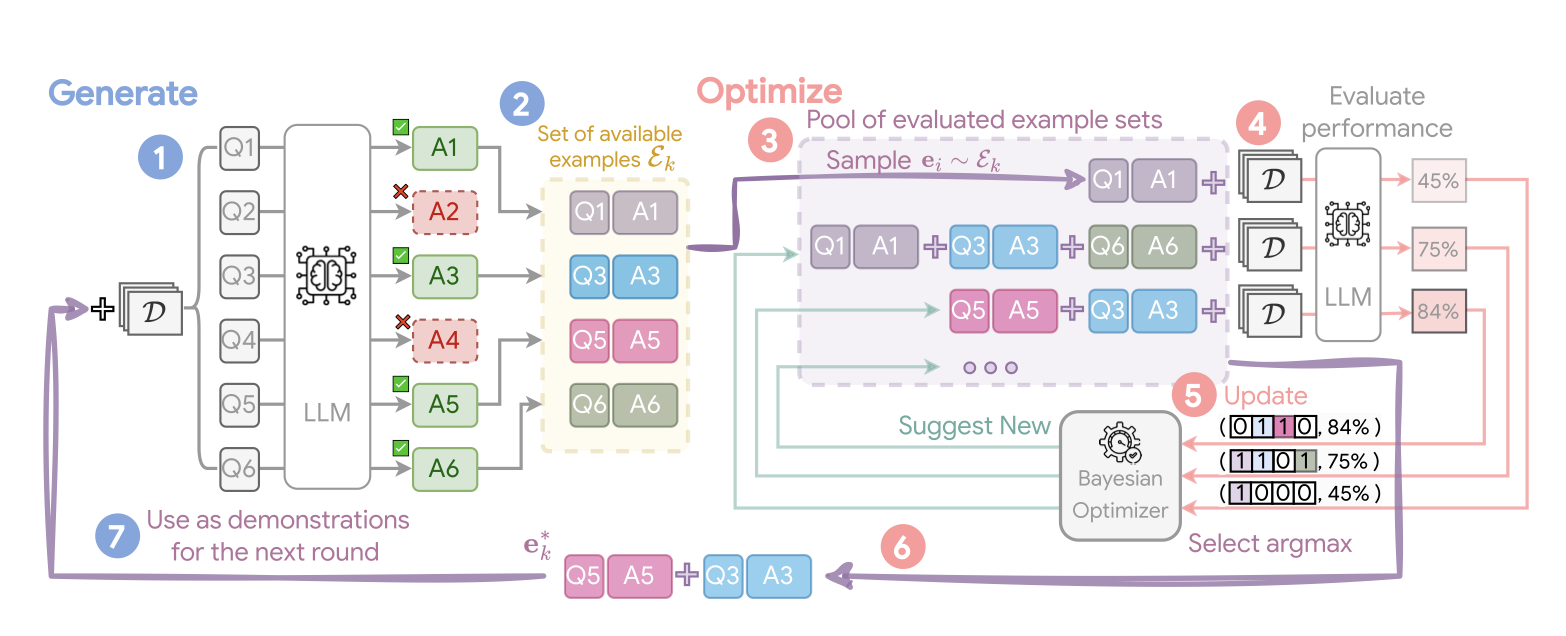
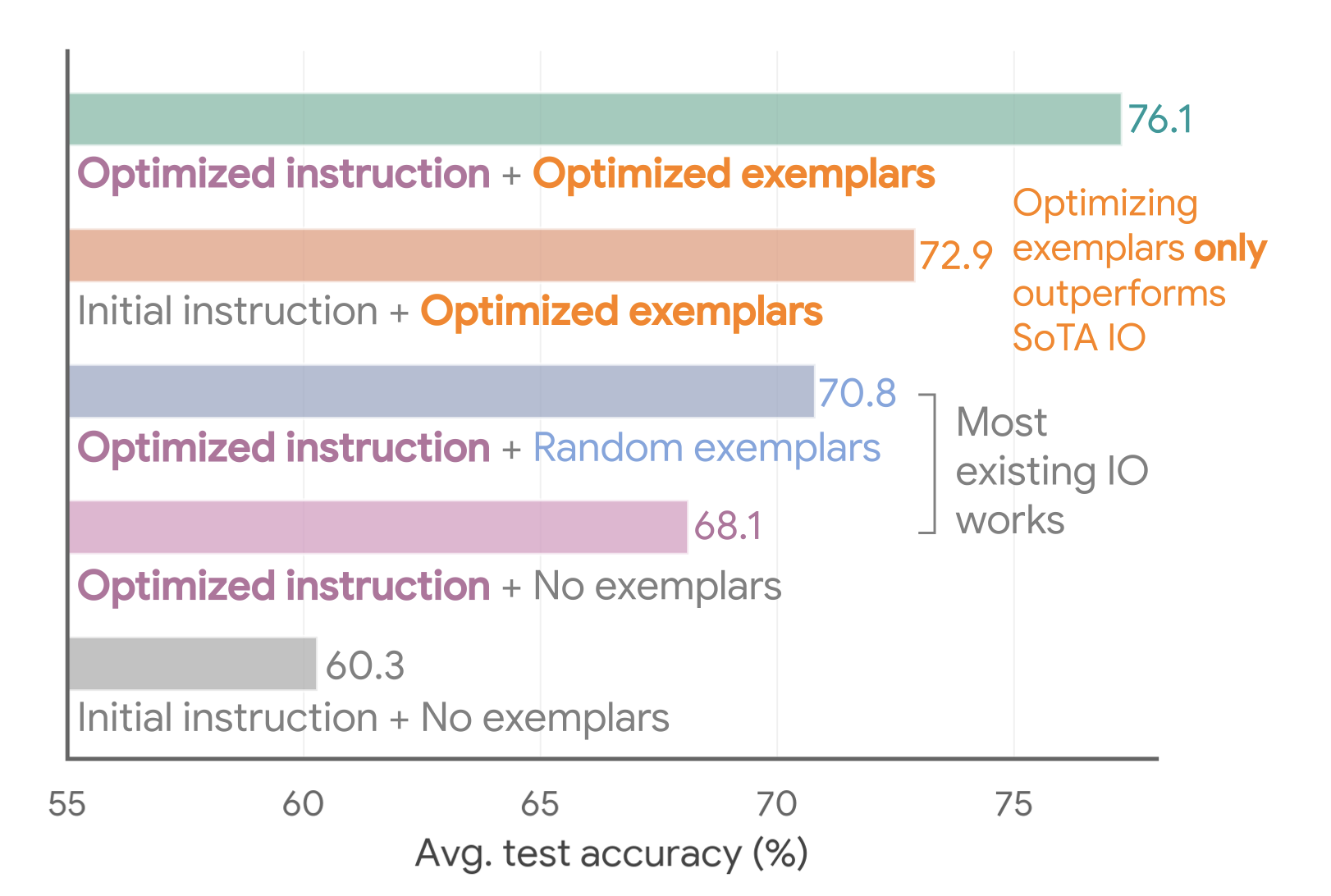 Teach Better or Show Smarter? On Instructions and Exemplars in Automatic Prompt OptimizationIn Advances in Neural Information Processing Systems 37. ☁️ Powers the Google Cloud Vertex AI Prompt Optimizer , 2024
Teach Better or Show Smarter? On Instructions and Exemplars in Automatic Prompt OptimizationIn Advances in Neural Information Processing Systems 37. ☁️ Powers the Google Cloud Vertex AI Prompt Optimizer , 2024