Abstract
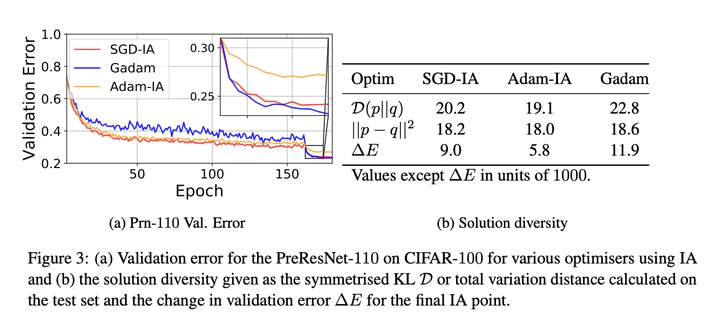
We analyse and explain the increased generalisation performance of Iterate Averaging using a Gaussian Process perturbation model between the true and batch risk surface on the high dimensional quadratic. Based on our theoretical results We derive three phenomena from our theoretical results: (1) The importance of combining iterate averaging with large learning rates and regularisation for improved regularisation (2) Justification for less frequent averaging. (3) That we expect adaptive gradient methods to work equally well or better with iterate averaging than their non adaptive counterparts. Inspired by these results, together with empirical investigations of the importance of appropriate regularisation for the solution diversity of the iterates, we propose two adaptive algorithms with iterate averaging. These give significantly better results than SGD, require less tuning and do not require early stopping or validation set monitoring. We showcase the efficacy of our approach on the CIFAR-10/100, ImageNet and Penn Treebank datasets on a variety of modern and classical network architectures.
Xingchen Wan
Research Scientist
My research interests include large language models, Bayesian optimization, AutoML, and machine learning on graphs.